Data Structure Design: (30 pts) Your task is to implement a representation of a railroad map. You have cities with names and locations, listed as (X,Y) coordinates, and railroad links between cities, with each link having a distance between those cities. The operations that will be performed most frequently (and therefore which must be performed quickly) are finding the nearest city to a given point (set of X,Y coordinates), and finding the shortest path from one city to another, traversing the rail lines.
- (10 pts) Write a data structure for this task as a C, Pascal, or C++ structure/record.
- (5 pts) Justify your selection in part (a). Contrast with at least one alternative organization.
- (10 pts) Write an algorithm for finding the nearest city to a given point, using your data structure.
- (5 pts) What is the complexity of your algorithm in part (c)?
Give your answer using big O notation, and tell whether you are
providing worst or average case, and absolute or amortized values.
- The most frequent operations are finding whether a record with a particular key value is in the database, and finding the record with the key value which is the immediate predecessor or immediate successor of a given key value..
- You have frequent insertions and deletions, as well as the above operations.
- Suppose you must find not just the immediate predecessor or successor, but the n closest key values (from a value that might or might not be in the database) (assume that insertions or deletions are very rare, once the database has been set up).
1 15 10 4 8 9 5 2 7.
- Show the resulting hash table using separate chaining.
- Show the results using in-place chaining.
- Show the results using linear probing.
- Show the results using double hashing. Assume the following secondary hash
function:
g(x) = x mod 6. - given the table resulting in part (d), add the value 8, using
Brent's algorithm.
- Show the inverted list structure for this data.
- Show the grid method, assuming values range from 0 to 20, and grids of size 4x4.
- Show the point quad-tree resulting from this data (show the tree structure, clearly labeling which child is which).
- Show the MX-quadtree for this data.
- Show the PR-quadtree for this data.
- Show the K-D Tree for this data.
- Show the Excell method for this data, assuming a bucket size of 2.
- Show the bit-interleaved values for these points counting X as the most significant.
- Show the results of linear hashing on these points, using as
hash function:
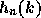 = k mod
= k mod 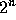 , where k is the
bit-interleaved
value computed in part (h)
, where k is the
bit-interleaved
value computed in part (h) - Show the results of order-preserving linear hashing, assuming
the hash function:
= (reverse k) mod , where the key
value for a point is the bit-interleaved value, computed in part (h). - show the 2-d range tree for this data.
- show the range priority tree for this data.